Parallel Transform
Kiba Pro's "Parallel Transform" provides an easy way to process a group of ETL rows at the same time using a pool of threads. It can be used to accelerate ETL transforms doing IO operations such as HTTP queries, by going multithreaded.
This is like avoiding N+1 queries in web development, but for ETL.
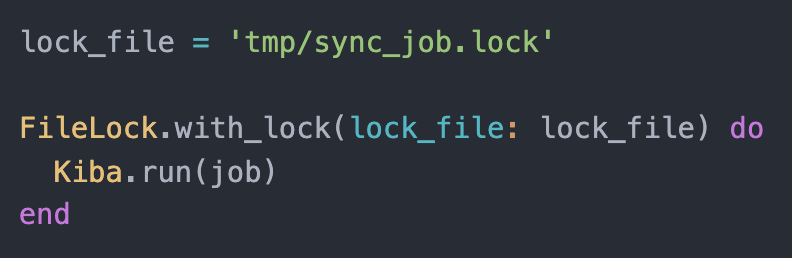
File Lock
In many cases (heavy synchronisations etc) it is important to ensure your ETL jobs will not overlap. Kiba Pro's "File Lock" makes it easy to ensure only a single copy of the job will run at a given time on a given host/machine.
A distributed version (using SQL advisory locks) is also available in beta.
Deep Sequel Integration
Sequel (by Jeremy Evans) is our preferred SQL library for Ruby ETL workloads. It is only natural that Kiba Pro provides a deep Sequel integration, based on our experience implementing data integrations, data migrations and datawarehouses, so you can solve such scenarios with less work & more reliably.
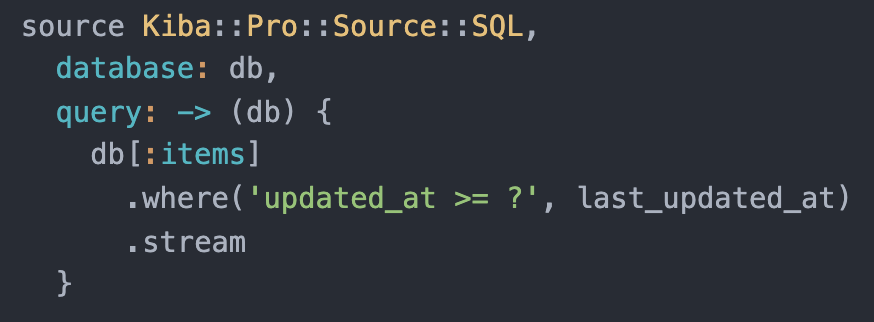
SQL Source
A flexible Kiba source for all Sequel-supported databases. Use raw SQL or the Sequel DSL to build your source Change Data Capture queries. Streaming and cursors available for MySQL and Postgres.
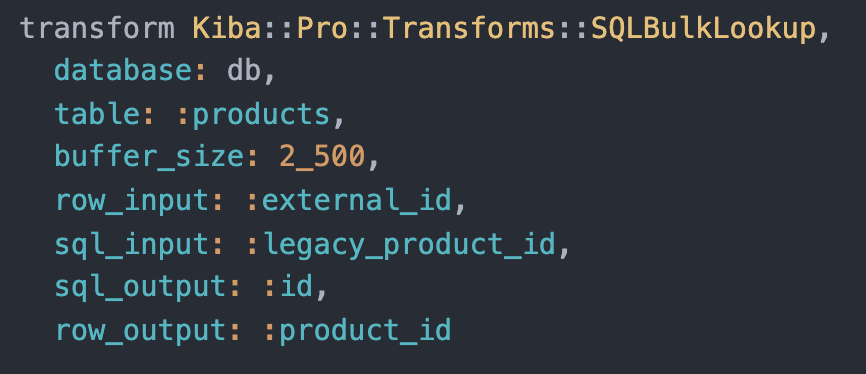
SQL Bulk Lookup
When importing records in your database, you'll have to "translate" reference columns (e.g. foreign keys, business keys) into internal references instead. Kiba Pro's Bulk Lookup transform handles these translations in bulk, to avoid a "N+1"-like effect, accelerating imports and making it easier to work on data migrations or datawarehouses scenarios.
SQL Bulk Insert and Upsert
A flexible yet efficient Kiba destination to insert or update SQL datastores (Postgres, MySQL). Supports multiple destinations in a single pass, transactional flushing for relationships, row-preprocessing. A must for any non-trivial synchronisation process to a SQL database!

Priority Support & Access to Consulting Services
Your Kiba Pro subscription gives you priority email support for any unforeseen issues and simple matters such as installation troubles.
Our consulting services will also be prioritized to Kiba Pro subscribers. If you need any coaching on ETL & data pipeline implementation, please reach out via email so we can discuss how to help you out!
All sales come with a two week, 100% money back guarantee.
Need to embed/distribute Kiba Pro to your customers?
Read the Commercial FAQ.